Google Hoạt Động Thế Nào? Hành Trình 4 Cửa Đưa Trang Của Bạn Lên Top

Vì sao bài hay mà vẫn "mất tích" trên Google?
Hãy tưởng tượng bạn vừa nấu một nồi phở ngon nhất phố. Nhưng quán bạn nằm trong con hẻm chưa có trên bản đồ, cửa thì khoá trái, và tấm biển hiệu thì quay vào trong. Phở ngon đến mấy cũng chẳng ai ăn — vì không ai tìm thấy, không ai vào được.
Trên internet, chuyện này xảy ra mỗi ngày: vô số bài viết tâm huyết nằm im lìm ở trang 5, trang 10 của Google, hoặc tệ hơn — không xuất hiện ở đâu cả. Chủ web ngơ ngác: "Bài tôi hay mà, sao không ai thấy?"
Câu trả lời gần như luôn nằm ở chỗ: bài đó kẹt ở một trong bốn cái cửa mà Google bắt mọi trang phải đi qua. Hiểu bốn cửa này, bạn sẽ tự chẩn đoán được 80% lý do "vì sao trang tôi không lên" — và quan trọng hơn, biết sửa ở đâu.
Ở bài tổng quan, ta đã ví Google như một ông thủ thư. Bài này ta mổ xẻ kỹ từng việc ông ấy làm, kèm cách bạn tự kiểm tra và sửa ở mỗi cửa. Bắt đầu nào.
Bốn cửa đó là gì? Một trang muốn có khách từ Google phải lần lượt: (1) được tìm thấy (Crawl) → (2) được lưu vào kho (Index) → (3) được xếp hạng (Rank) → (4) được hiển thị (Serve). Rớt ở cửa nào, chết ở cửa đó. Cả bài này đi qua từng cửa một.
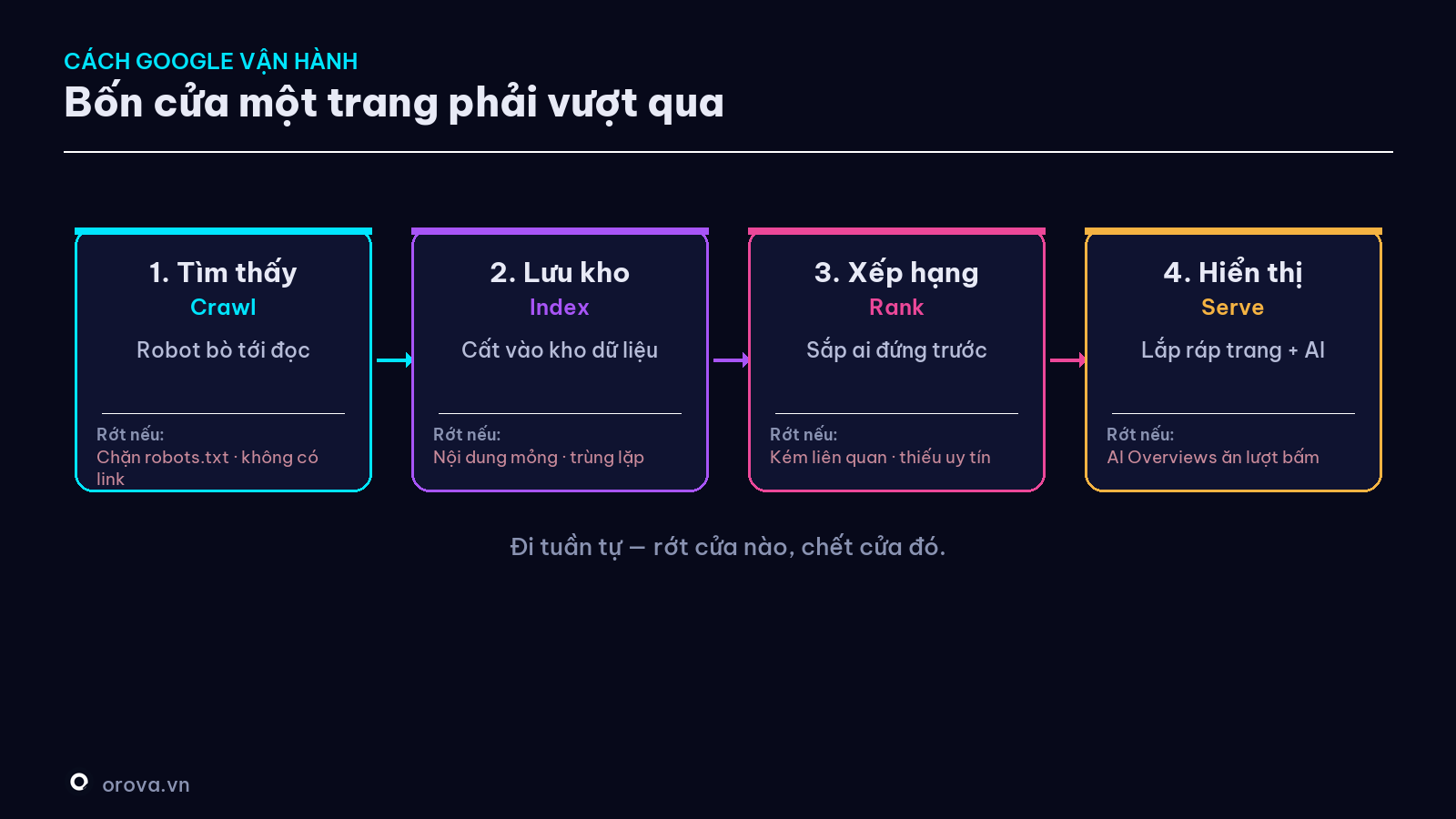
Cửa 1 — Tìm thấy (Crawl): robot Google có "bò" tới trang bạn không?
Bản chất. Google có những con robot tự động (gọi là Googlebot) đi khắp internet, lần theo các đường link để phát hiện và đọc nội dung từng trang. Việc đi-và-đọc đó gọi là crawl ("bò"). Nếu robot chưa bao giờ bò tới trang bạn, thì với Google, trang đó không tồn tại.
"Crawl" nghĩa là gì? Tiếng Anh là "bò". Đây là việc robot Google bò khắp web đọc nội dung. "Google đã crawl trang tôi chưa?" = "robot đã ghé đọc trang tôi chưa?"
Quy trình: Google tìm thấy một trang mới như thế nào
- Google đã biết một số trang (từ lần crawl trước, từ sitemap bạn nộp).
- Khi bò vào các trang đó, nó thấy các đường link trỏ đi nơi khác → lần theo để phát hiện trang mới.
- Trang mới được đưa vào "hàng chờ" để bò tới đọc.
Suy ra điều cực quan trọng: một trang không có đường link nào trỏ tới (từ trang khác hoặc từ sitemap) thì Google gần như không bao giờ tìm thấy. Đây là lý do bài mới đăng cần được gắn link từ trang chủ/chuyên mục, và cần có mặt trong sitemap.
Sitemap là gì? Một file liệt kê tất cả các trang trên website của bạn, nộp cho Google để nó biết đường mà bò vào — như đưa cho ông thủ thư bản danh mục sách của bạn. Thường ở địa chỉ
tênmiền.com/sitemap.xml.
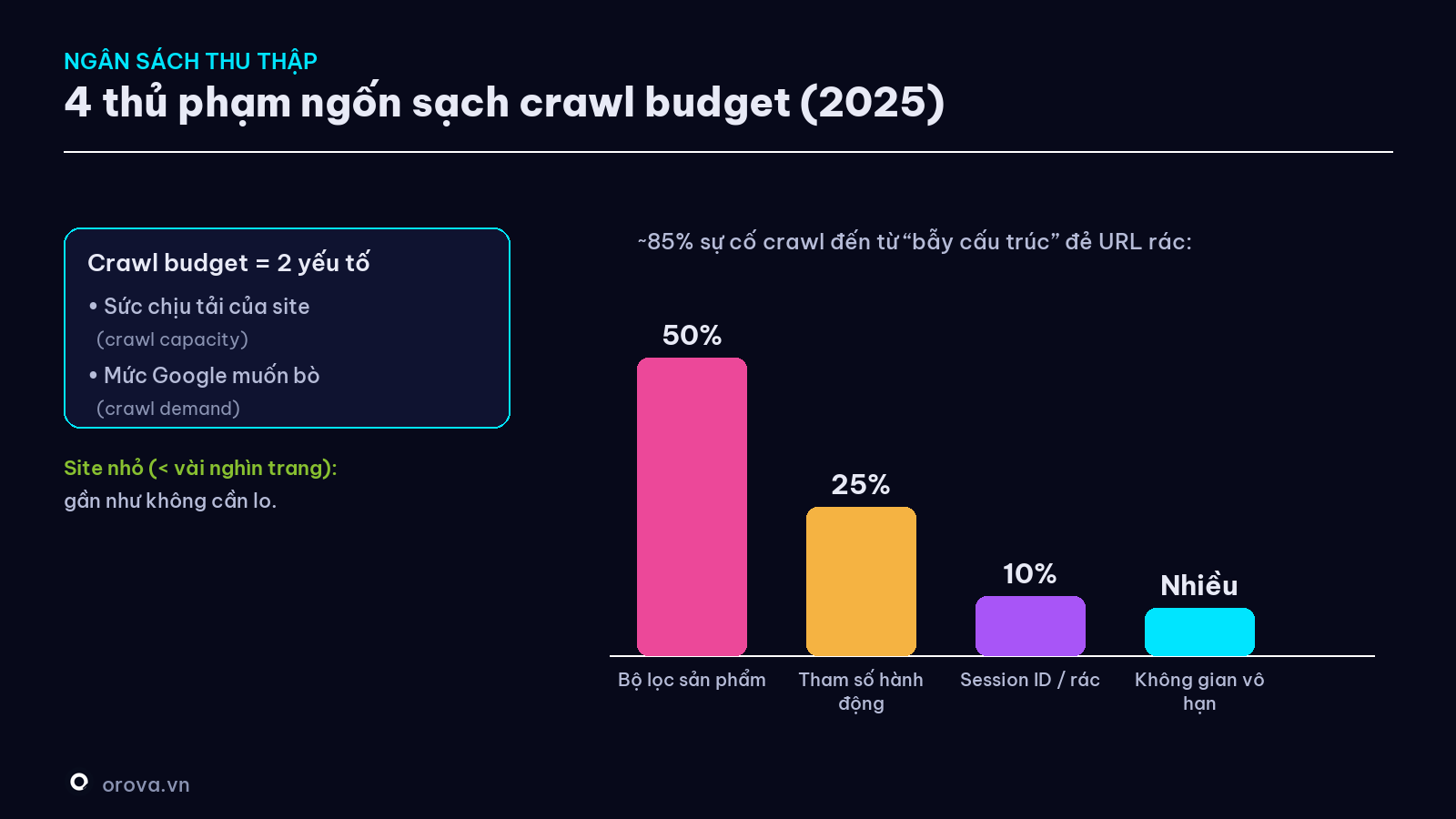
"Ngân sách thu thập" (crawl budget) — và 4 thủ phạm ngốn sạch nó
Google không bò vô hạn. Mỗi website được phân một ngân sách thu thập — quyết định bởi hai thứ: site chịu tải được bao nhiêu (crawl capacity) và Google muốn bò bao nhiêu (crawl demand, dựa trên độ lớn, độ tươi, chất lượng, độ phổ biến của site). (Nguồn: Google Search Central.)
Tin tốt cho người mới: site nhỏ (vài trăm trang) gần như không cần lo crawl budget — Google bò hết dễ dàng. Chỉ site lớn (hàng chục nghìn trang trở lên) mới cần tối ưu, để robot không phí thời gian vào các trang vô giá trị.
Và đây là phần đắt giá: theo dữ liệu Google 2025, gần 85% sự cố crawl nghiêm trọng đến từ các "cái bẫy cấu trúc" sinh ra hàng loạt URL vô dụng. Bốn thủ phạm lớn nhất:
- Bộ lọc sản phẩm (faceted navigation) — ~50%: trang thương mại điện tử cho lọc theo màu/giá/size, mỗi tổ hợp lọc đẻ ra một URL → bùng nổ hàng nghìn URL gần như trùng nhau.
- Tham số hành động (action parameters) — 25%: các link kiểu
?them-vao-gio=true,?wishlist=add— chỉ là hành động, không phải trang nội dung, nhưng Google vẫn coi là URL riêng. - Session ID / tham số rác — 10%: mỗi khách được gắn một mã phiên vào URL (
?sid=12345) → Google thấy mỗi lượt là một trang mới. - "Không gian vô hạn": lịch/widget sự kiện tự đẻ URL cho mọi ngày/tổ hợp → hàng triệu trang vô giá trị.
Hướng dẫn: tự kiểm tra & sửa Cửa 1
- Kiểm tra robot có bị chặn không: mở
tênmiền.com/robots.txt. Nếu thấy dòngDisallow: /→ bạn đang cấm Google vào toàn bộ site. Đây là lỗi tai hại số 1, thường do lập trình viên quên gỡ khi đưa web từ bản thử lên thật. - Nộp sitemap: vào Google Search Console → mục Sitemaps → dán
sitemap.xml→ Submit. - Gắn link nội bộ cho bài mới từ trang chủ hoặc chuyên mục, để robot có đường bò tới nhanh.
Lợi ích khi làm đúng Cửa 1: bài mới được Google phát hiện trong vài giờ tới vài ngày thay vì vài tuần — nội dung của bạn "có cửa" cạnh tranh sớm hơn.
Tiêu chuẩn "đạt" ở Cửa 1: không có dòng chặn nhầm trong robots.txt; sitemap đã nộp và Google báo "Success"; bài quan trọng đều có ít nhất một link nội bộ trỏ tới.
Cửa 2 — Lưu vào kho (Index): được đọc rồi, có được giữ không?
Đây là cửa khiến nhiều người vỡ mộng nhất, vì nó phản trực giác: robot bò tới đọc trang bạn KHÔNG có nghĩa là Google sẽ giữ nó. Đọc xong, Google còn phải quyết định có đáng cất vào kho hay không.
"Index" (lập chỉ mục) là gì? Là kho lưu trữ các trang Google đã đọc và quyết định giữ lại. "Trang tôi đã được index" = đã nằm trong kho, đủ điều kiện xuất hiện khi có người tìm. "Chưa index" = Google biết trang tồn tại nhưng chưa cất → người ta tìm cũng không ra.
Vì sao một trang bị từ chối vào kho?
Trong Google Search Console có báo cáo "Pages" (Trang), liệt kê trang nào được index, trang nào không và vì sao. Hai trạng thái "đau lòng" hay gặp nhất:
- "Discovered – currently not indexed" (Đã phát hiện – hiện chưa index): Google biết trang tồn tại nhưng chưa thèm bò tới, thường vì nghi ngờ chất lượng thấp hoặc đang tiết kiệm ngân sách thu thập.
- "Crawled – currently not indexed" (Đã bò tới – hiện chưa index): Google đã đọc rồi nhưng quyết định không cất. Đây gần như luôn là tín hiệu: nội dung bị coi là mỏng, trùng lặp, hoặc kém giá trị. (Nguồn: Google Search Console.)
Các lý do phổ biến khiến trang không vào kho:
- Nội dung mỏng (thin content): quá ít chữ, không có giá trị thật.
- Trùng lặp: nhiều trang gần như y hệt → Google chỉ giữ một bản.
- Bị gắn
noindex(lệnh "đừng lưu trang này") — đôi khi do vô tình sót lại từ lúc dựng web. - Soft 404: trang báo "không tìm thấy sản phẩm" nhưng vẫn trả mã "bình thường" → Google bối rối, không cất.
"Thẻ canonical" cứu bạn khỏi nạn trùng lặp. Khi một nội dung xuất hiện ở nhiều đường dẫn, thẻ canonical chỉ cho Google biết "bản gốc cần tính là cái này" — gom điểm uy tín về một chỗ thay vì chia năm xẻ bảy.

Quy trình & Hướng dẫn: kiểm tra một trang đã vào kho chưa
- Cách nhanh, thô: gõ lên Google
site:tênmiền.com/đường-dẫn-bài. Có hiện ra = đã index. - Cách chuẩn, chi tiết: dùng công cụ Kiểm tra URL (URL Inspection) trong Google Search Console — dán địa chỉ bài vào ô trên cùng. Nó cho biết: trang đã index chưa, lần bò gần nhất khi nào, Google chọn bản chuẩn (canonical) nào, và có lỗi gì.
- Test trực tiếp: bấm "Test Live URL" để Google bò thử ngay tức thì — xem ảnh chụp trang như Google "nhìn thấy", và các lỗi (kể cả lỗi JavaScript che mất nội dung).
- Xin index thủ công: nếu trang ổn mà chưa được lưu, bấm "Request Indexing" để đẩy vào hàng chờ ưu tiên.
Bẫy JavaScript ít người biết: nếu website của bạn dựng bằng công nghệ hiện đại mà nội dung chỉ hiện ra sau khi trình duyệt chạy mã JavaScript, đôi khi Google đọc trang lúc nội dung chưa kịp hiện → tưởng trang trống. Công cụ "Test Live URL" sẽ cho thấy điều này qua ảnh chụp. (Nguồn: Google Search Central.)
Lợi ích khi làm đúng Cửa 2: mọi bài đáng giá đều nằm trong kho Google, sẵn sàng xuất hiện — thay vì âm thầm bị bỏ rơi dù bạn đã tốn công viết.
Tiêu chuẩn "đạt" ở Cửa 2: trong báo cáo "Pages" của GSC, số trang index khớp với số bài thật bạn muốn công khai; không có bài quan trọng nào kẹt ở "Crawled – currently not indexed".
Cửa 3 — Xếp hạng (Rank): trong kho có ngàn trang, vì sao chọn bạn?
Khi có người tìm, Google lôi từ kho ra các trang phù hợp rồi sắp thứ tự ai trước ai sau. Đây là phần "bí mật" nhất — không ai biết công thức chính xác, và nó đổi liên tục. Nhưng mọi tín hiệu đều quy về ba câu hỏi lớn:
- Liên quan không? Trang có khớp đúng ý định người tìm không? (Gõ "cách làm X" mà ra trang bán X là lệch.)
- Đáng tin không? Nội dung có chất lượng, website có uy tín không (đây là vai trò của E-E-A-T và backlink — có bài chuyên sâu riêng).
- Trải nghiệm tốt không? Trang tải nhanh, dùng được trên điện thoại, không gây khó chịu?
Đừng cố "học thuộc" hàng trăm yếu tố xếp hạng trên mạng. Phần lớn là suy đoán. Thứ chắc chắn đúng: trang trả lời nhu cầu tốt nhất, từ nguồn đáng tin nhất, với trải nghiệm tốt nhất, sẽ thắng. Mỗi nhánh trong ba câu hỏi trên có một bài chuyên sâu riêng trong cẩm nang (từ khoá & ý định, nội dung & E-E-A-T, kỹ thuật & tốc độ).
Tiêu chuẩn "đạt" ở Cửa 3: trang của bạn vào được top 20–30 cho từ khoá mục tiêu trong vài tháng. Chưa vào nổi top 30 thường không phải lỗi xếp hạng tinh vi, mà là nội dung chưa đủ tốt hoặc lệch ý định — quay lại Cửa nội dung.
Cửa 4 — Hiển thị (Serve): xếp hạng cao rồi vẫn có thể "đói khách"
Đây là cửa mới trở nên sống còn từ 2024, và là chỗ nhiều người làm SEO kiểu cũ vấp ngã. Ngày xưa, lên #1 (qua Cửa 3) gần như chắc chắn có khách. Nay thì không.
Vì Google không còn "trả về 10 đường link" nữa, mà lắp ráp cả một trang kết quả gồm: đoạn trả lời do AI tự viết (AI Overviews) trên cùng, hộp trả lời nhanh (Featured Snippet), khối "Mọi người cũng hỏi", hình ảnh, video... rồi bên dưới tất cả mới tới các link xanh truyền thống.
Hệ quả: bạn có thể đứng #1 ở Cửa 3 mà vẫn mất phần lớn lượt bấm ở Cửa 4 — vì một đoạn AI đã trả lời thẳng câu hỏi phía trên bạn. (Chi tiết về AI Overviews và cách "được AI trích dẫn" nằm ở bài tổng quan và các bài GEO.)
Tiêu chuẩn "đạt" ở Cửa 4: không chỉ nhắm "lên top", mà nhắm được Google chọn vào các phần nổi bật — lọt hộp trả lời nhanh, được trích trong đoạn AI. Mẹo: trả lời câu hỏi thật gọn, rõ, có cấu trúc (đoạn 40–60 chữ, danh sách, hoặc bảng).
Ghép lại: cây chẩn đoán "vì sao bài tôi không lên"
Đây là phần đáng giá nhất — lần sau bài không có khách, đừng đoán mò. Đi ngược từ dưới lên theo bốn cửa:
- Trang đã được index chưa? (gõ
site:hoặc dùng URL Inspection.) - Chưa → bạn kẹt ở Cửa 1 hoặc 2. Kiểm tra robots.txt, sitemap, chất lượng nội dung. - Đã index rồi — nó xếp hạng ở đâu? (xem Search Console.) - Ngoài top 30 → vấn đề Cửa 3: nội dung chưa đủ tốt hoặc lệch ý định tìm kiếm.
- Xếp hạng tốt mà vẫn ít khách? - → nghi Cửa 4: có thể một đoạn AI hoặc hộp trả lời đang "ăn" lượt bấm. Kiểm tra trang kết quả thực tế của từ khoá đó.
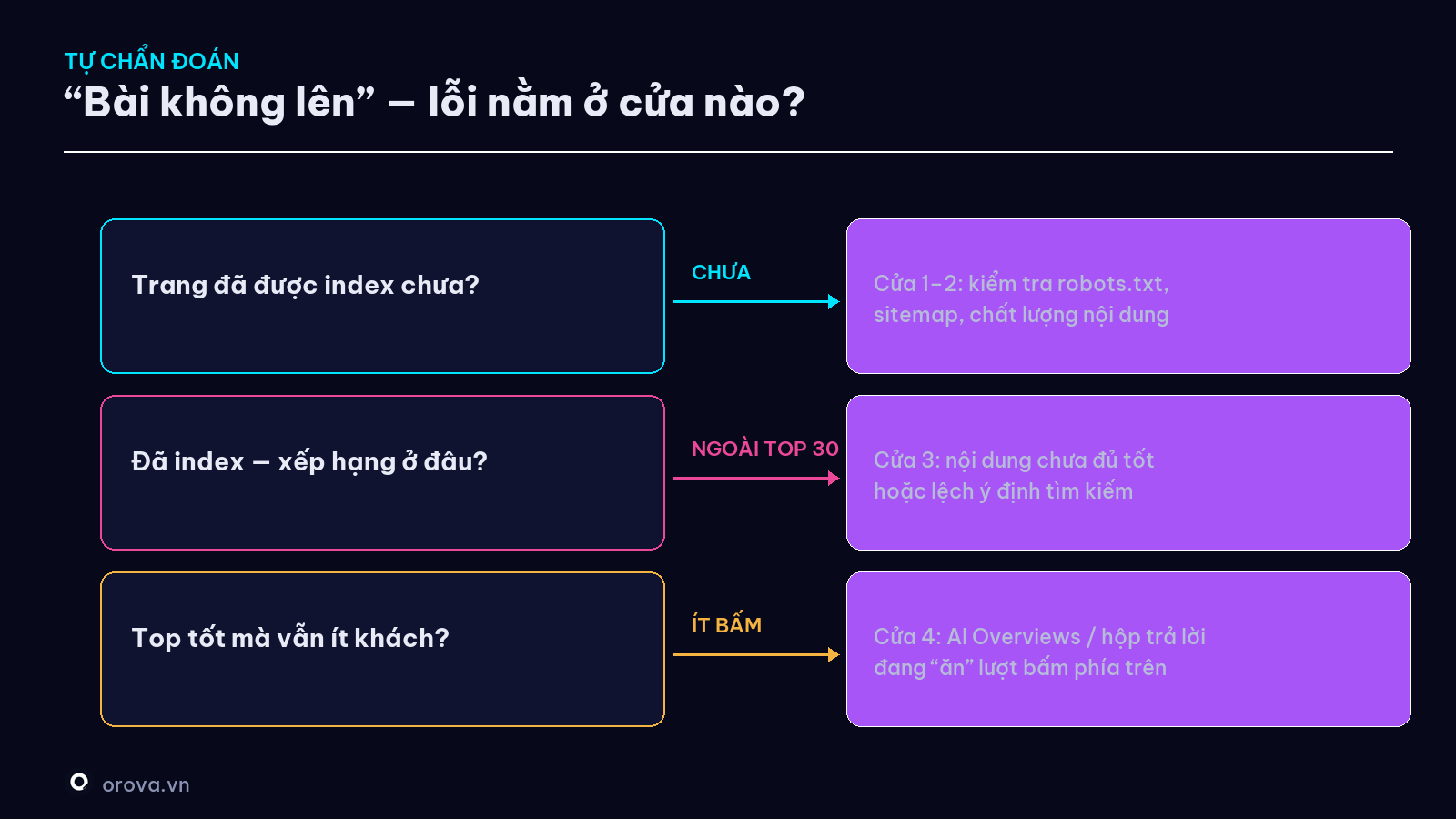
Bắt đúng cửa, sửa đúng chỗ. Đó là khác biệt giữa người loay hoay "đổi đủ thứ mà không lên" và người sửa trúng bệnh trong một buổi chiều.
Câu hỏi thường gặp
Bài mới đăng bao lâu thì Google index? Từ vài giờ tới vài tuần, tuỳ uy tín site và ngân sách thu thập. Muốn nhanh: nộp sitemap + gắn link nội bộ + dùng "Request Indexing" trong Search Console.
Tôi cần lo "ngân sách thu thập" không? Nếu site dưới vài nghìn trang thì gần như không. Crawl budget chỉ là vấn đề lớn với site rất lớn (thương mại điện tử, tin tức nhiều chục nghìn trang).
Google index trang rồi sao vẫn không có khách? Index chỉ là điều kiện cần. Có khách hay không phụ thuộc Cửa 3 (xếp hạng) và Cửa 4 (hiển thị). Index xong mới là vạch xuất phát, không phải đích đến.
"Crawled – currently not indexed" sửa thế nào? Đây là Google nói "đọc rồi nhưng thấy chưa đáng giữ". Cách sửa: nâng chất nội dung (sâu hơn, độc đáo hơn), gộp các trang mỏng/trùng lại, đảm bảo trang trả lời đúng một nhu cầu rõ ràng.
Bài viết thuộc bộ Cẩm nang SEO toàn ngành của Orova. Đây là bài chuyên sâu trong cụm — xem bài tổng quan "SEO Toàn Tập 2026" để có bức tranh lớn. Bắt đầu cùng Orova tại orova.vn/vi/seo.
Nguồn tham khảo
Google Search Central (Crawl Budget Management; Crawling December; Fix JavaScript Problems) · Google Search Console Help (URL Inspection; Pages report) · Stan Ventures (Top crawl budget killers 2025) · Search Engine Land (Crawl budget 2025; URL Inspection use cases).
Để AI Agent lo SEO cho bạn
Orova tự lên kế hoạch, viết bài, tối ưu và theo dõi thứ hạng — bạn chỉ việc đọc kết quả.
Dùng thử miễn phí