How Google Works: The 4 Gates That Get Your Page to the Top

Why does a great page still go "missing" on Google?
Imagine you've cooked the best bowl of pho on the street. But your shop is down an alley that isn't on the map, the door is locked, and the sign faces inward. No matter how good the pho is, nobody eats it — because no one can find it, no one can get in.
This happens online every day: countless heartfelt articles sit silent on page 5 or 10 of Google — or worse, appear nowhere at all. The owner is baffled: "My article is good — why does no one see it?"
The answer almost always is: that page is stuck at one of four gates Google makes every page pass through. Understand these gates and you can self-diagnose 80% of "why won't my page rank" — and, more importantly, know where to fix it.
In the overview guide we compared Google to a librarian. Here we dissect each job that librarian does, plus how you check and fix things at every gate. Let's go.
What are the four gates? A page that wants Google traffic must, in order: (1) be found (Crawl) → (2) be stored (Index) → (3) be ranked (Rank) → (4) be served (Serve). Fall at any gate, fail at that gate. This whole guide walks through them one by one.

Gate 1 — Found (Crawl): does Google's robot even reach your page?
The essence. Google has automated robots (called Googlebot) that roam the internet, following links to discover and read each page. That roaming-and-reading is called crawling. If the robot has never reached your page, then as far as Google is concerned, it doesn't exist.
What's "crawl"? It means to roam/crawl. It's Google's robot roaming the web reading content. "Has Google crawled my page?" = "has the robot dropped by and read it?"
The process: how Google finds a new page
- Google already knows some pages (from previous crawls, from the sitemap you submitted).
- Crawling those pages, it sees links pointing elsewhere → it follows them to discover new pages.
- The new page enters a queue to be crawled.
This implies something crucial: a page with no links pointing to it (from another page or a sitemap) is almost never found by Google. That's why a new post needs links from your homepage/category pages, and needs to be in the sitemap.
What's a sitemap? A file listing all the pages on your website, submitted to Google so it knows the way in — like handing the librarian your catalog. Usually at
yourdomain.com/sitemap.xml.
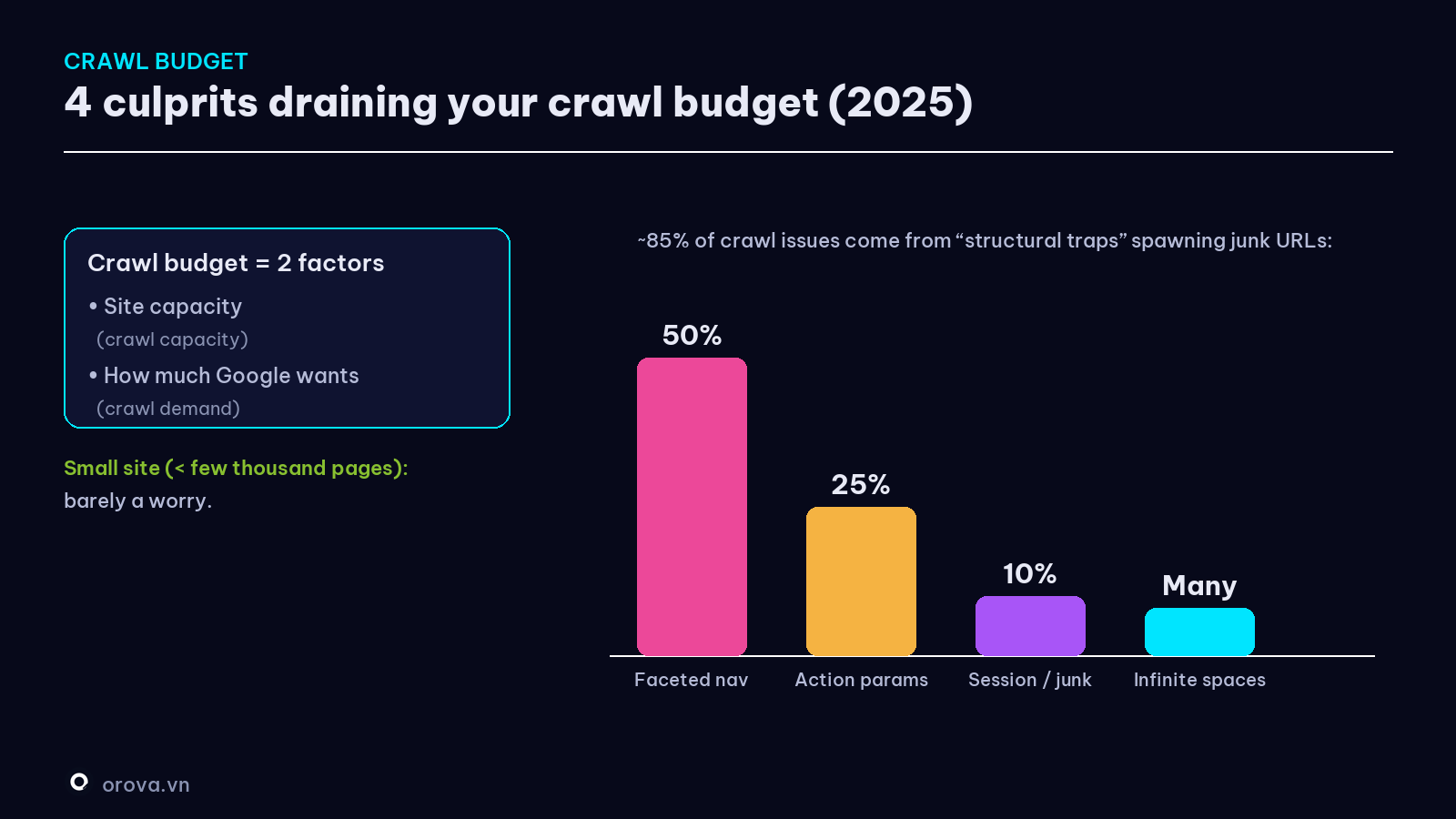
"Crawl budget" — and the 4 culprits that drain it
Google doesn't crawl endlessly. Each site gets a crawl budget — set by two things: how much the site can handle (crawl capacity) and how much Google wants to crawl (crawl demand, based on the site's size, freshness, quality, and popularity). (Source: Google Search Central.)
Good news for beginners: a small site (a few hundred pages) barely needs to worry about crawl budget — Google crawls it all easily. Only large sites (tens of thousands of pages) need to optimize so the robot doesn't waste time on worthless URLs.
And here's the valuable part: per Google's 2025 data, nearly 85% of serious crawl issues come from "structural traps" that spawn piles of useless URLs. The four biggest culprits:
- Faceted navigation — ~50%: e-commerce filters by color/price/size, where each combination spawns a URL → thousands of near-duplicate URLs explode.
- Action parameters — 25%: links like
?add-to-cart=true,?wishlist=add— these are actions, not content pages, but Google still treats them as separate URLs. - Session IDs / junk parameters — 10%: each visitor gets a session code in the URL (
?sid=12345) → Google sees every session as a new page. - Infinite spaces: calendars/event widgets spawn a URL for every date/combination → millions of worthless pages.
How-to: check & fix Gate 1 yourself
- Check if the robot is blocked: open
yourdomain.com/robots.txt. If you seeDisallow: /→ you're banning Google from the whole site. This is the #1 catastrophic mistake, often left behind when a developer moves a site from staging to live. - Submit your sitemap: in Google Search Console → Sitemaps → paste
sitemap.xml→ Submit. - Add internal links to new posts from the homepage or category pages, so the robot has a path in quickly.
Benefit of getting Gate 1 right: new posts get discovered in hours-to-days instead of weeks — your content gets a fair shot at competing sooner.
"Pass" standard for Gate 1: no accidental blocking line in robots.txt; sitemap submitted and reporting "Success"; every important page has at least one internal link pointing to it.
Gate 2 — Stored (Index): read is not the same as kept
This is the gate that disappoints people most, because it's counterintuitive: the robot reaching your page does NOT mean Google will keep it. After reading, Google still decides whether it's worth storing.
What's "index"? The warehouse of pages Google has read and decided to keep. "My page is indexed" = it's in the warehouse, eligible to appear when someone searches. "Not indexed" = Google knows the page exists but hasn't stored it → searchers won't find it.
Why is a page denied storage?
Google Search Console has a "Pages" report listing which pages are indexed, which aren't, and why. The two most common painful statuses:
- "Discovered – currently not indexed": Google knows the page exists but hasn't bothered crawling it yet, often suspecting low quality or saving crawl budget.
- "Crawled – currently not indexed": Google read it but decided not to store it. This is almost always a signal: the content is seen as thin, duplicate, or low-value. (Source: Google Search Console.)
Common reasons a page doesn't get stored:
- Thin content: too few words, no real value.
- Duplication: many near-identical pages → Google keeps only one.
- Tagged
noindex(a "don't store this page" instruction) — sometimes left over by accident from building the site. - Soft 404: a page says "product not found" but still returns a "normal" status code → Google gets confused and doesn't store it.
The "canonical" tag saves you from duplication. When one piece of content appears at several URLs, the canonical tag tells Google "the master to count is this one" — consolidating authority into one place instead of splitting it.

How-to: check whether a page is in the warehouse
- Quick & rough: search Google for
site:yourdomain.com/your-post-path. If it shows up = indexed. - Proper & detailed: use the URL Inspection tool in Google Search Console — paste the post URL into the top box. It tells you: whether it's indexed, last crawl time, which canonical Google chose, and any issues.
- Live test: click "Test Live URL" to have Google crawl it on the spot — see a screenshot of how Google "sees" the page, and any errors (including JavaScript errors hiding content).
- Request indexing manually: if the page is fine but unstored, click "Request Indexing" to push it into the priority queue.
A JavaScript trap few know: if your site is built with modern tech where content only appears after the browser runs JavaScript, Google sometimes reads the page before the content loads → thinks it's blank. "Test Live URL" reveals this via its screenshot. (Source: Google Search Central.)
Benefit of getting Gate 2 right: every worthwhile post sits in Google's warehouse, ready to appear — instead of being silently dropped despite your effort.
"Pass" standard for Gate 2: in the GSC "Pages" report, the indexed count matches the number of posts you actually want public; no important post is stuck at "Crawled – currently not indexed."
Gate 3 — Ranked (Rank): a thousand pages in the warehouse — why pick you?
When someone searches, Google pulls fitting pages from the warehouse and orders them. This is the most "secret" part — no one knows the exact formula, and it changes constantly. But every signal boils down to three big questions:
- Relevant? Does the page match the searcher's intent? (Searching "how to make X" and getting a page selling X is a mismatch.)
- Trustworthy? Is the content quality and the site authoritative (the role of E-E-A-T and backlinks — each has its own deep-dive)?
- Good experience? Does the page load fast, work on phones, and avoid annoyance?
Don't try to "memorize" the hundreds of ranking factors online. Most are guesswork. What's certain: the page that best answers the need, from the most trustworthy source, with the best experience, wins. Each branch above has its own deep-dive in this series (keywords & intent, content & E-E-A-T, technical & speed).
"Pass" standard for Gate 3: your page reaches the top 20–30 for its target keyword within a few months. Not even cracking the top 30 usually isn't some subtle ranking issue — it's content that isn't good enough or is off-intent. Back to the content gate.
Gate 4 — Served (Serve): even a high rank can still starve
This gate became make-or-break from 2024, and it's where old-school SEO trips up. Once upon a time, hitting #1 (via Gate 3) almost guaranteed traffic. Not anymore.
Because Google no longer "returns 10 links" — it assembles a whole results page: an AI-written answer (AI Overviews) on top, a quick-answer box (Featured Snippet), a "People Also Ask" block, images, videos... and only below all of that come the traditional blue links.
The result: you can be #1 at Gate 3 yet lose most of your clicks at Gate 4 — because an AI answered the question above you. (Details on AI Overviews and how to "get cited by AI" are in the overview guide and the GEO articles.)
"Pass" standard for Gate 4: don't just aim to "rank" — aim to get chosen for the prominent features: land the quick-answer box, get cited in the AI block. Tip: answer the real question concisely and clearly (a 40–60 word passage, a list, or a table).
Putting it together: the "why won't my page rank" decision tree
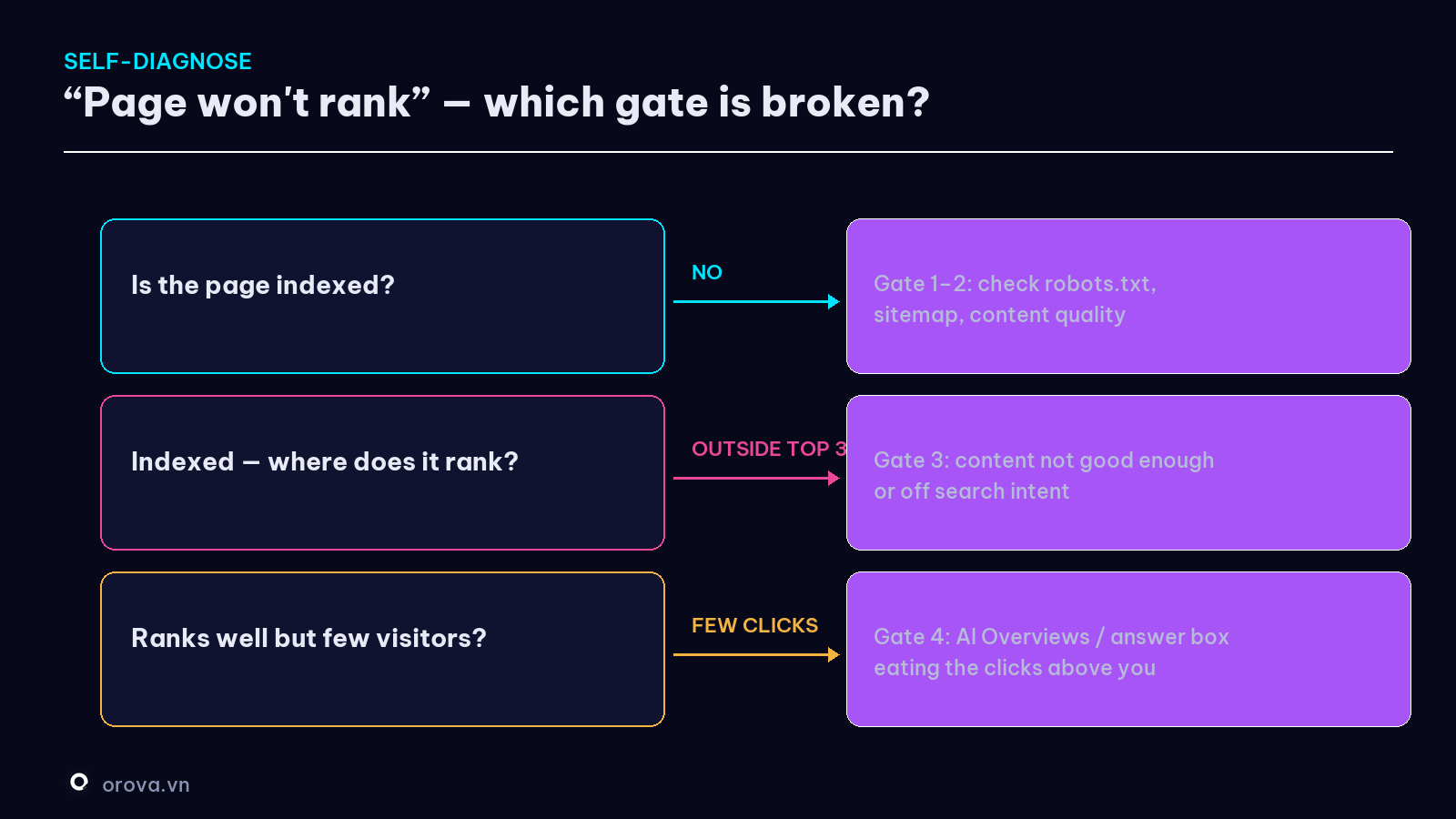
This is the most valuable part — next time a page gets no traffic, don't guess. Go bottom-up through the four gates:
- Is the page indexed? (use
site:or URL Inspection.) - No → you're stuck at Gate 1 or 2. Check robots.txt, sitemap, content quality. - Indexed — where does it rank? (check Search Console.) - Outside the top 30 → a Gate 3 problem: content isn't good enough or is off-intent.
- Ranks well but still few visitors? - → suspect Gate 4: an AI box or answer box may be eating clicks. Check the actual results page for that keyword.
Diagnose the right gate, fix the right spot. That's the difference between someone fumbling "I changed everything and it still won't rank" and someone who fixes the real illness in one afternoon.
FAQ
How long until Google indexes a new post? Hours to weeks, depending on site authority and crawl budget. To speed it up: submit a sitemap + add internal links + use "Request Indexing" in Search Console.
Do I need to worry about "crawl budget"? If your site is under a few thousand pages, almost never. Crawl budget is only a big issue for very large sites (e-commerce, news, tens of thousands of pages).
Google indexed my page but I still get no traffic — why? Indexing is only necessary, not sufficient. Traffic depends on Gate 3 (ranking) and Gate 4 (serving). Indexed is the starting line, not the finish.
How do I fix "Crawled – currently not indexed"? That's Google saying "I read it but didn't find it worth keeping." Fix: raise content quality (deeper, more original), merge thin/duplicate pages, and make sure the page clearly answers one real need.
This article is part of Orova's complete SEO guide series. It's a deep-dive within the cluster — see the overview "SEO in 2026" for the big picture. Get started with Orova at orova.vn/en/seo.
Sources
Google Search Central (Crawl Budget Management; Crawling December; Fix JavaScript Problems) · Google Search Console Help (URL Inspection; Pages report) · Stan Ventures (Top crawl budget killers 2025) · Search Engine Land (Crawl budget 2025; URL Inspection use cases).
Let an AI Agent handle your SEO
Orova plans, writes, optimizes, and tracks rankings on its own — you just read the results.
Try it free